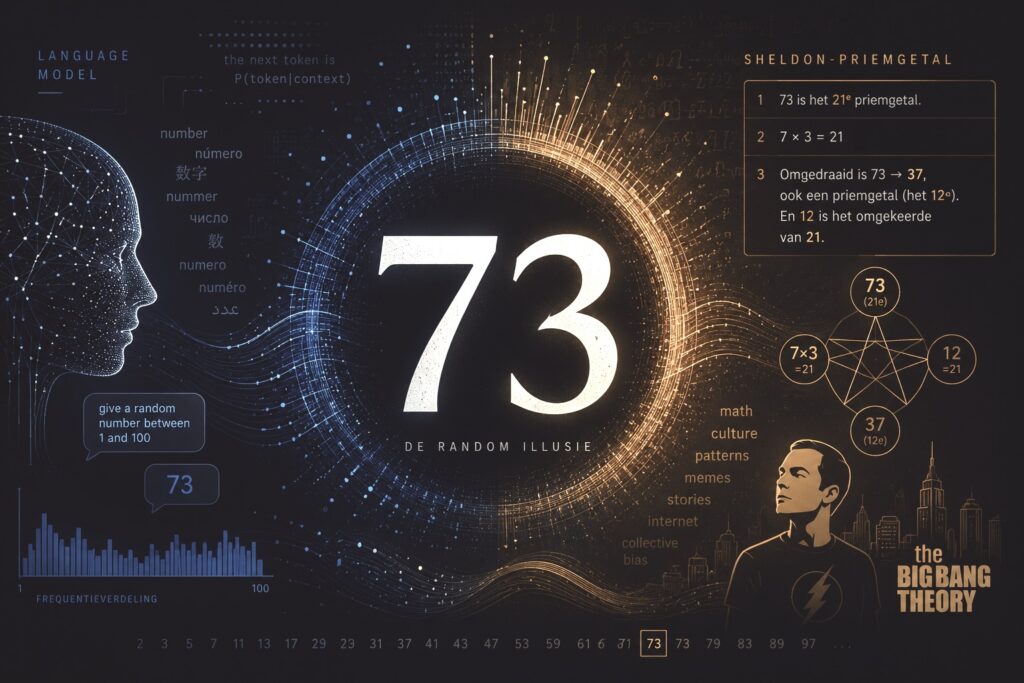
Afgelopen week las ik een interessant LinkedIn-bericht van Ajuna Soerjadi over een opvallend fenomeen: wanneer je ChatGPT vraagt een willekeurig getal tussen 1 en 100 te kiezen, komt het blijkbaar vaak uit op 73. Is dat echt zo en en zo ja, hoe kan een probabilistisch systeem zulke consistente voorkeurspatronen vertonen?
Om dat beter te begrijpen ben ik verder in het fenomeen gedoken en stuitte ik op het onderzoek Deterministic or probabilistic? The psychology of LLMs as random number generators uit 2025 van Javier Coronado-Blázquez. De studie onderzoekt hoe large language models als GPT reageren wanneer ze gevraagd worden een willekeurig getal te kiezen.
Voor het onderzoek voerde Coronado-Blázquez 75.600 modelcalls uit op zes taalmodellen. De tests werden uitgevoerd in zeven talen en met verschillende temperatuurinstellingen. Daarbij werd steeds dezelfde vraag gesteld: “Geef een random getal tussen 1 en X.”
Een temperatuurinstelling beïnvloedt hoeveel variatie ontstaat bij het selecteren van een volgend token of woorddeel. Een lage temperatuur maakt antwoorden voorspelbaarder doordat vooral de meest waarschijnlijke opties gekozen worden. Een hogere temperatuur vergroot de kans op minder waarschijnlijke antwoorden en dus op meer variatie. In theorie zou dat tot meer willekeur moeten leiden, maar de studie laat zien dat dit effect beperkt blijft. Zelfs bij temperatuur 2.0 keerden modellen vaak terug naar dezelfde voorkeursgetallen. Een hogere temperatuur vergroot de spreiding, maar neemt de onderliggende voorkeuren niet weg.
De resultaten laten zien dat taalmodellen geen uniforme willekeur produceren. Binnen een range van 1 tot 5 kozen modellen vooral 3 of 4. Bij 1 tot 10 kwam 7 duidelijk vaker voor. In de range van 1 tot 100 doken vooral 37, 47 en 73 steeds weer op.
Er waren ook verschillen tussen modellen. GPT-4o-mini, Gemini 2.0 en Phi-4 bleken relatief beperkt in hun spreiding en produceerden vaak één dominant antwoord. Llama 3.1 en DeepSeek-R1 lieten meer variatie zien. DeepSeek-R1 viel daarnaast op doordat het uitgebreide chain-of-thought-redeneringen genereerde voordat het een getal produceerde. Ondanks die langere redeneringen kwam ook dit model vaak terug bij dezelfde voorkeursgetallen.
Ook taal en trainingsdata maakten verschil. Gemini koos in Spaanse prompts vaker 3 binnen de range 1–5, terwijl het model in Engelse prompts vaker 4 koos. DeepSeek-R1 liet in Chinese prompts andere voorkeuren zien dan in Europese talen. Volgens de onderzoekers wijst dit erop dat naast modelarchitectuur ook culturele patronen en taalverdelingen in trainingsdata invloed hebben op de uitkomsten.
Volgens Coronado-Blázquez ontstaat dit gedrag doordat een taalmodel geen randomgenerator is, maar een systeem dat het meest waarschijnlijke volgende token voorspelt op basis van trainingsdata. Wanneer mensen online vaak 73 of 37 noemen als “willekeurig” getal, leert het model dat zulke antwoorden waarschijnlijk zijn in die context. Het model reproduceert daarmee menselijke voorkeuren en culturele patronen.
De studie verwijst onder meer naar experimenten van het YouTube-kanaal Veritasium, waarbij ongeveer 200.000 mensen een willekeurig getal gaven tussen 1 en 100. Mensen kozen opvallend vaak 37, 73, 77 en 7, terwijl ronde getallen als 10, 50 en 100 relatief weinig gekozen werden. De onderzoekers gebruiken dit experiment als illustratie van het feit dat mensen zelf ook geen uniforme willekeur produceren. Het is te simplistisch om te stellen dat dit specifieke experiment direct invloed heeft gehad op taalmodellen. Waarschijnlijker is dat zowel de experimenten als de modellen dezelfde bredere taal- en cultuurpatronen weerspiegelen die ook in trainingsdata voorkomen.

Als aanvulling op het onderzoek bouwde ik zelf in Perplexity een dashboard dat de “randomness” van enkele taalmodellen vergelijkt op basis van 1.000 gegenereerde getallen per model. Ook daarin verschenen duidelijke voorkeursgetallen. GPT-4o produceerde opvallend vaak 73, gevolgd door onder meer 42, 69 en 7. Claude 3.5 Sonnet liet eveneens een duidelijke piek bij 73 zien, terwijl Gemini Pro relatief meer spreiding liet zien maar alsnog verhoogde frequentie bij 73 en enkele andere getallen vertoonde. De uitkomsten sluiten daarmee aan bij de patronen die Coronado-Blázquez in zijn onderzoek beschrijft: de modellen genereren geen uniforme willekeur, maar vertonen terugkerende statistische voorkeuren die waarschijnlijk samenhangen met trainingsdata, culturele patronen en samplinggedrag.
O ja, en 73 is ook nog het Sheldon priemgetal 😉
Bronnen
- Coronado-Blázquez, J. (2025). Deterministic or probabilistic? The psychology of LLMs as random number generators. arXiv.
- Soerjadi, A. (2024). Als je aan ChatGPT vraagt om een random getal tussen 1 en 100 te kiezen. LinkedIn.
- Veritasium. (2024). Why is this number everywhere?. YouTube.


